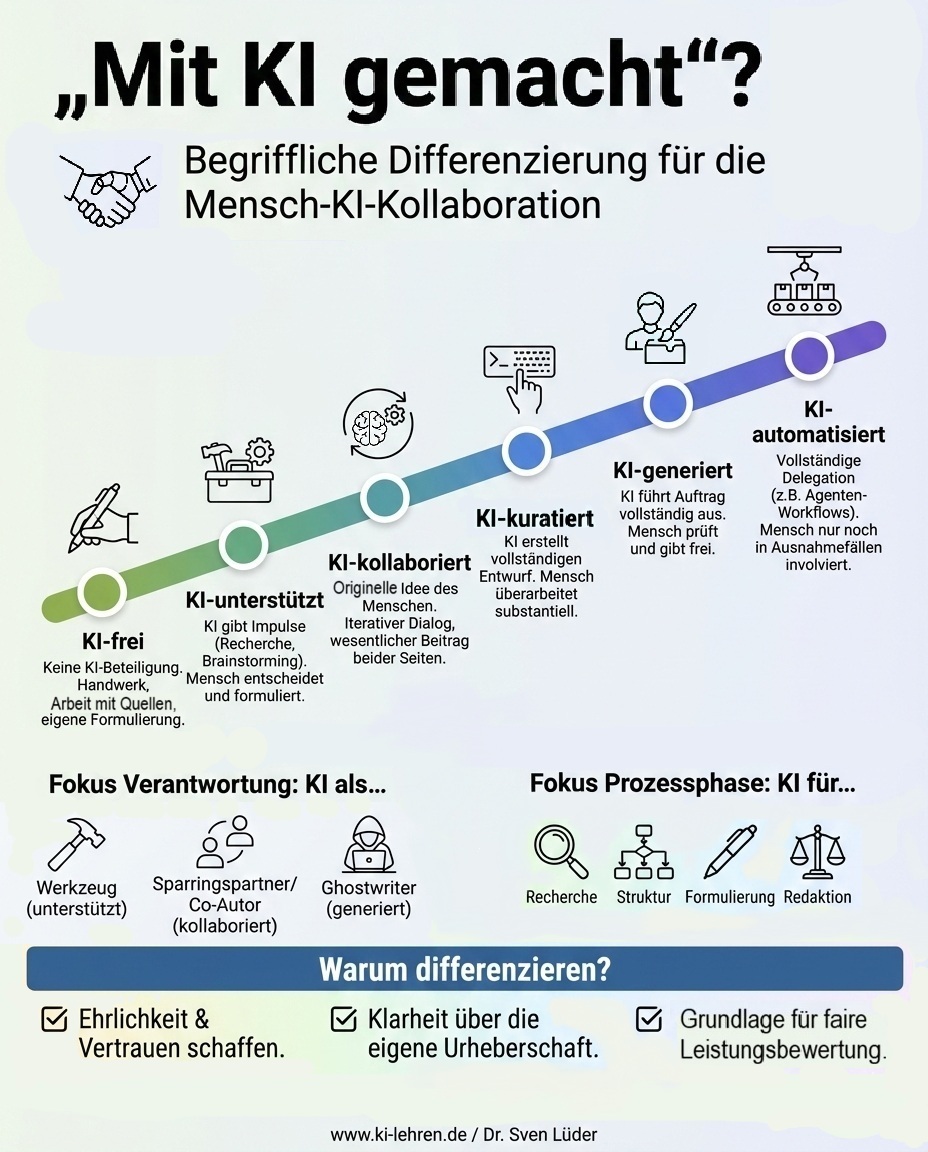
„Mit KI gemacht?"
Warum wir eine differenzierte Sprache für Mensch-KI-Kollaborationen brauchen: Ein Stufenmodell von KI-frei bis KI-automatisiert.
Artikel lesenVor einigen Tagen habe ich zufällig den KI-Kompetenz-Analyzer von Manuel Flick entdeckt, einem Lehrer und KI-Fortbildner, von dessen Arbeit ich über LinkedIn einen positiven Eindruck gewonnen habe. Flicks Tool bietet Lehrkräften einen Selbsttest zur Einschätzung ihrer KI-Kompetenzen, aufgeteilt in mehrere Dimensionen, mit sofortiger Auswertung und Handlungsempfehlungen. Das ist im Wesentlichen dasselbe, was mein eigener KI-Kompetenz-Check tut, den ich einige Wochen nach Flick veröffentlicht hatte, ohne von seinem Tool zu wissen. Im Detail gibt es einige Unterschiede: Flicks Analyzer baut auf einem von ihm mitentwickelten schuldidaktischen Kompetenzmodell mit den Kategorien Verstehen, Anwenden, Reflektieren und Mitgestalten auf; meiner nutzt andere Kategorien und stellt darum andere Fragen. Letztlich ähnlich sich nur 2 von 18 (bei mir) bzw. 24 Fragen (bei Flick). Das Grundkonzept aber ist nahezu identisch, und beide richten sich dezidiert an Lehrkräfte (bei Flick: zudem an Lernende).
Es wäre naheliegend zu denken, ich hätte bei Flick abgeschaut. Das habe ich aber nicht. Stattdessen habe ich offensichtlich das gleiche KI-Modell wie er benutzt, um meinen Kompetenz-Check zu entwickeln. Tatsächlich stammte auch die Idee dazu von Claude (und genau das ist das Problem), nachdem ich den Chatbot um Vorschläge für interessante Coding-Projekte bat. Die KI lieferte. Ich entschied mich für einen von sechs Vorschlägen und erhielt sodann einen Entwurf, den ich im iterativen Dialog nur noch verfeinerte. Claude versicherte mir auf Nachfrage, dass ein vergleichbares Tool für Lehrkräfte nicht existiere. Ich hatte auch selbst recherchiert, aber offenbar nicht gründlich genug. Hat Claude sich an Flicks Tool orientiert, ohne es mir zu sagen? Oder sind Flick und ich zu ähnlichen Ergebnissen gelangt, weil wir dasselbe LLM benutzen? Das weiß ich nicht. Beide Erklärungen wären so plausibel wie problematisch.
Eine aktuelle Arbeit von Earp et al. in Nature Machine Intelligence (2025) spricht vom „Provenance Problem": einem systematischen Bruch in der Kette intellektueller Zuschreibung. Ein LLM reproduziert Ideen aus Quellen, die der Nutzer nie gelesen hat und die das Modell nicht nennt. Die Herkunft verschwindet in einer Blackbox.
Die Autoren grenzen das Phänomen klar ab. Einerseits gibt es klassische Plagiate, die Vorsatz voraussetzen. Andererseits kennt die Psychologie eine Kryptomnesie: Man hält eine früher aufgenommene Idee für eine eigene, weil die Erinnerung an die Quelle verblasst ist. LLM-vermittelte Übernahmen sind etwas Drittes: weder Vorsatz noch vergessene Erinnerung. Der Nutzer hat die Quelle nie gekannt. Earp et al. sprechen von einem „Verdunsten der moralischen Verantwortung". Niemand handelt fahrlässig, das Ergebnis ist dennoch eine Übernahme, für die niemand verantwortlich zeichnet.
Das Risiko wächst mit dem Grad der KI-Beteiligung. Wer KI nur zur Recherche nutzt, formuliert und strukturiert selbst. Wer KI-kuratiert oder KI-generiert arbeitet, überlässt dem Modell die Ausarbeitung und damit die Möglichkeit, Strukturen und Konzepte aus seinen Trainingsdaten oder Online-Recherchen zu reproduzieren, ohne dass es auffällt.
Neben unbeabsichtigten Einzelübernahmen gibt es ein strukturelles Problem. Wenn Millionen Menschen mit denselben Modellen arbeiten, trainiert auf denselben Daten, konvergieren die Ergebnisse. Nicht weil jemand abschreibt, sondern weil die Werkzeuge systematisch ähnliche Outputs erzeugen.
Die Evidenz dafür ist robust. Moon et al. analysierten 2.200 College-Essays und zeigten: KI-unterstützte Texte sind individuell nicht schlechter, aber kollektiv deutlich homogener. Die Diversität sinkt messbar, und der Effekt wächst mit der Skalierung. Zhou et al. fanden in einer Longitudinalstudie, dass die Homogenität auch nach Entzug der KI erhöht bleibt: eine „kreative Narbe" im Denken. Ein aktueller Aufsatz in Nature von Traberg et al. warnt vor einer entstehenden „wissenschaftlichen Monokultur", weil alle dieselben KI-Workflows nutzen.
Das Phänomen der „Multiple Discovery", das die Wissenschaftssoziologie seit Robert K. Merton kennt, war schon immer real: Bei ähnlichen Voraussetzungen kommt es zu parallelen Entdeckungen. KI verstärkt diesen Effekt aber ungemein, weil die Technologie die Voraussetzungen angleicht. Ob Flick und ich unabhängig voneinander auf dieselbe Idee kamen oder ob Claude Flicks Konzept reproduziert hat, lässt sich nicht klären. Aber die Wahrscheinlichkeit solcher Konvergenzen steigt mit jedem Menschen, der KI nutzt.
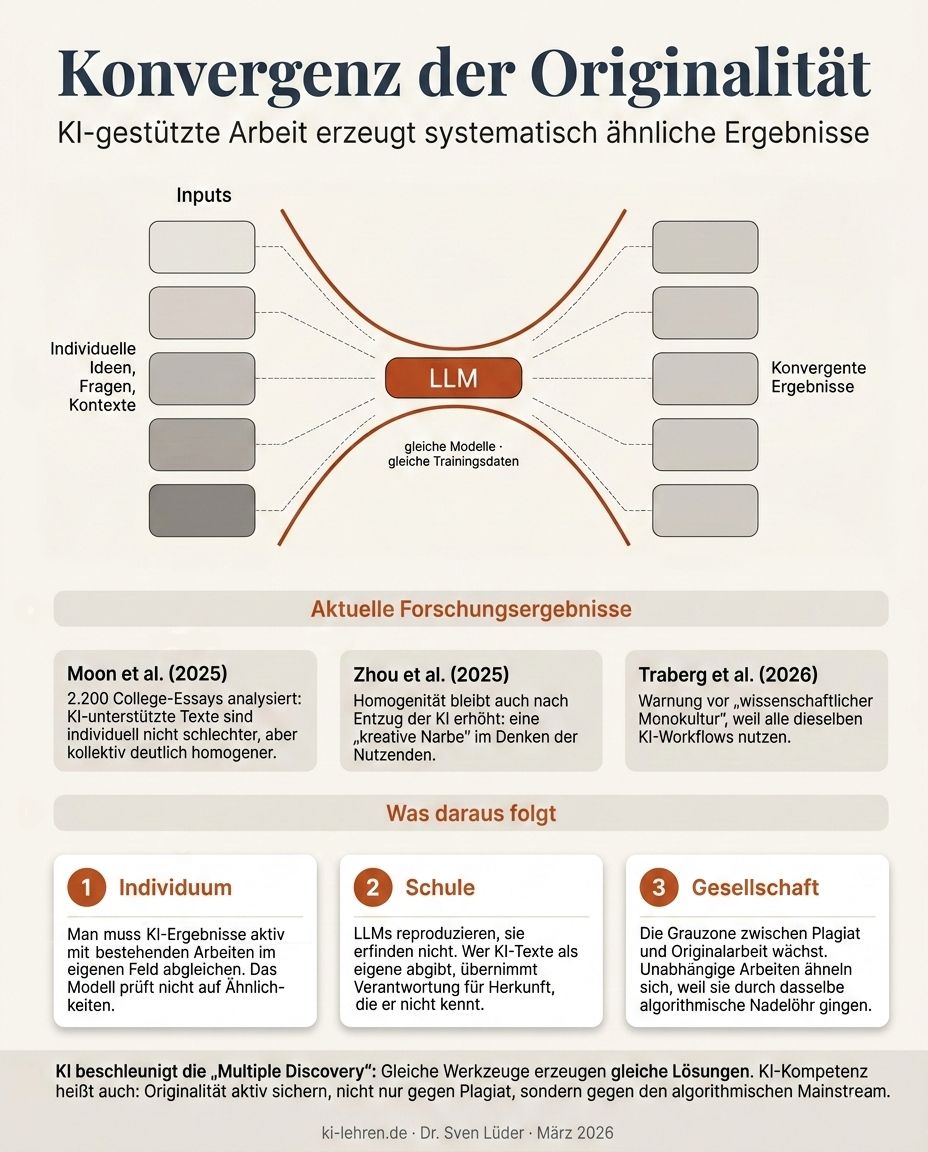
Für den eigenen Workflow: Wer auf den oberen Stufen des Stufenmodells arbeitet, muss aktiv prüfen, ob das Ergebnis Ähnlichkeiten mit bestehenden Arbeiten aufweist. Das Modell weist nicht darauf hin. Sich im eigenen Feld auszukennen ist wichtiger geworden als je zuvor: Nur wer weiß, was andere erarbeitet haben, erkennt, ob das, was die KI liefert, tatsächlich neu ist.
Für den Unterricht: Schüler*innen müssen verstehen, dass ein LLM keine originelle Denkmaschine ist, sondern ein System, das auf unzähligen Quellen aufsitzt, die es nicht offenlegt. Wer einen KI-generierten Text als eigene Arbeit abgibt, übernimmt Verantwortung für etwas, dessen Herkunft er nicht kennt.
Für die Gesellschaft: Die binäre Unterscheidung zwischen Plagiat und Originalarbeit reicht nicht mehr aus. Es gibt einen wachsenden Graubereich von Arbeiten, die unabhängig voneinander entstanden sind und sich dennoch ähneln, weil sie durch dasselbe algorithmische Nadelöhr gegangen sind. Nicht weniger Aufmerksamkeit für Übernahmen ist nötig, sondern ein differenzierteres Verständnis dafür, wie sie entstehen.
Und im Zweifel: Transparenz. Ich habe Manuel Flick kontaktiert und die Ähnlichkeit offen angesprochen. Das ist das Mindeste.
KI-Kompetenz reflektiert aufbauen: In meinen Workshops erarbeiten wir gemeinsam, wie Sie KI auf verschiedenen Stufen der Kollaboration einsetzen, die Herkunft von KI-Ergebnissen kritisch einordnen und Ihren Schüler*innen einen verantwortungsvollen Umgang mit KI-generierten Inhalten vermitteln können.
© Dr. Sven Lüder, www.ki-lehren.de
Warum wir eine differenzierte Sprache für Mensch-KI-Kollaborationen brauchen: Ein Stufenmodell von KI-frei bis KI-automatisiert.
Artikel lesenVier Strategien für wirksame Prüfungsformate: Prävention, Adaption, Motivation und Innovation.
Artikel lesenKI beherrscht kombinatorische Kreativität – aber Vorstellungskraft, Vision und Urteilsvermögen lassen sich nicht delegieren.
Artikel lesen